Engineering a Self Improving Multi Agent RAG System
As companies grow, knowledge gets scattered everywhere.Business logic lives in backend services, product decisions are buried in docs, and metrics are hidden inside SQL dashboards. Simple questions like:
“How exactly is placement rate calculated?”
suddenly require multiple people to answer. Over time, this becomes expensive. Engineers spend time answering repetitive questions.Support teams become bottlenecks. Business teams wait hours -- sometimes days for simple operational clarity. I wanted to build a system that could act as a unified intelligence layer for the organization.
Something that could:
- Answer process questions
- Explain code logic
- Query live data
- Understand business context
- And eventually automate safe operational tasks
That’s how this multi-agent RAG system started.Instead of using one giant LLM prompt with every tool attached to it, I moved to a multi-agent architecture where each agent specializes in one type of task.
The Architecture
The system has one parent orchestrator, one shared context-enrichment layer, and multiple domain-specific specialist agents. The orchestrator’s job is to understand the user query and prepare it for the right downstream agent. But the important detail is this:
The query is enriched before it reaches the specialist agent.
That means the parent orchestrator does not immediately send the raw user question to a Data Agent, Knowledge Agent, or Executor Agent. Instead, it first passes the request through the Hybrid RAG Engine. The Hybrid RAG Engine gathers relevant context from docs, code, SQL models, dashboards, schemas, and past corrections. Once the request is enriched, the orchestrator can route it to the right specialist. There are also multiple versions of each specialist agent based on domain.
For example:
- Domain A Data Agent
- Domain B Data Agent
- Domain A Knowledge Agent
- Domain B Knowledge Agent
- Domain-specific Executor Agents
- .....
This matters because different teams often use different definitions, systems, metrics, and workflows. A generic Data Agent might misunderstand a question, but a domain-specific Data Agent can answer using the right business conte
Here’s the full flow:
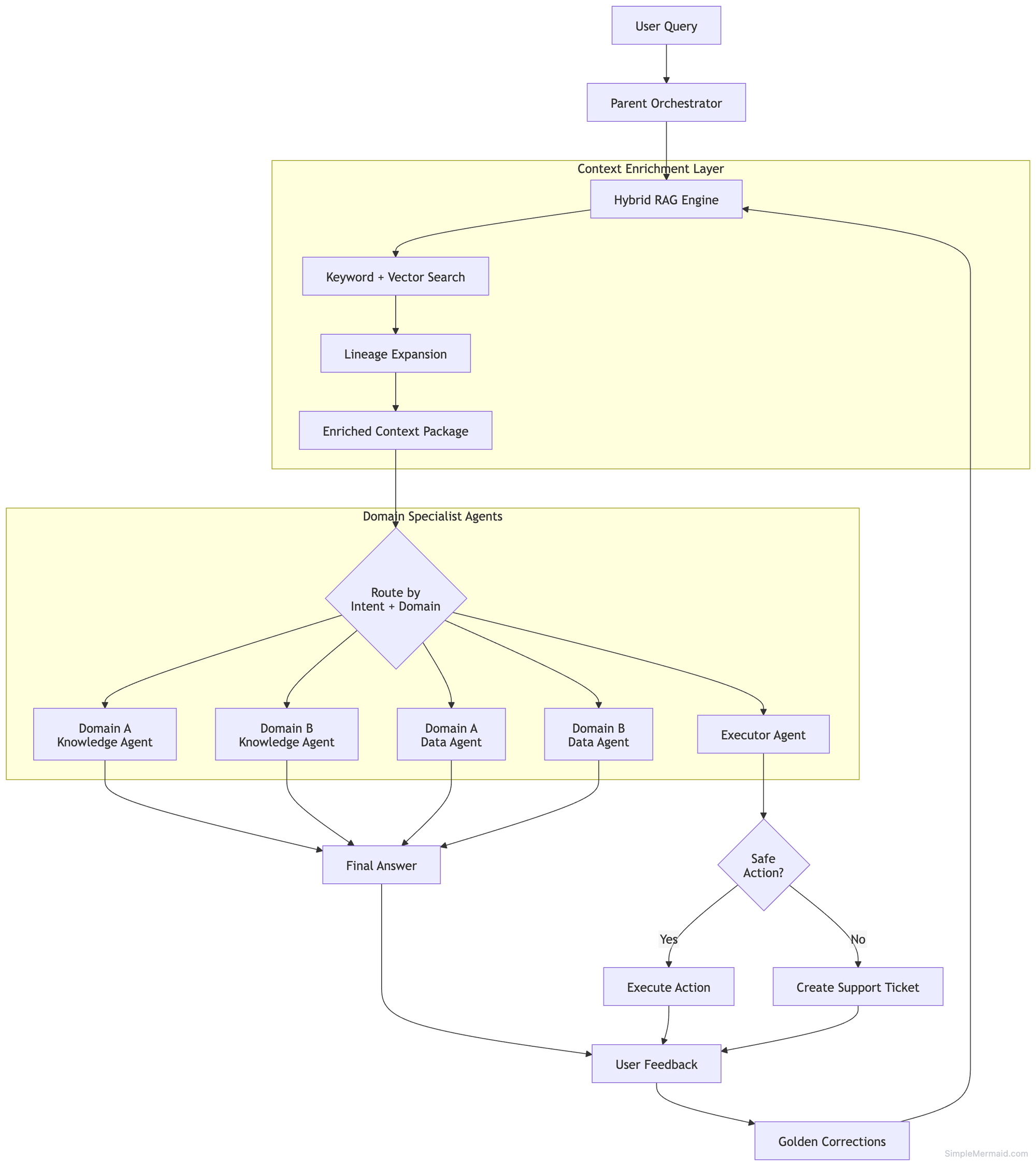
The Knowledge Agents handle:
- Docs
- Codebases
- Product logic
- System architecture
The Data Agents handle:
- KPI questions
- SQL generation
- Dashboard explanations
- Metric definitions
- Structured analysis
The Executor Agent handles safe operational actions.
For example:
- “Can you reset this workflow?”
- “Can you re-run this sync?”
- “Can you update this configuration?”
If the request falls within a verified list of safe actions, the Executor Agent can perform it automatically. Anything outside that safe boundary is never executed blindly. Instead, the system automatically creates a support ticket and routes it to the appropriate human team. That safety layer ended up being extremely important because it allows automation without losing operational control.
Why Standard RAG Wasn’t Enough
Traditional RAG works fine for FAQs.But enterprise systems are relational. A metric definition might exist in:
- A wiki page
- A dbt model
- Backend transformation code
- Dashboard SQL
Simple vector similarity misses those relationships. So I built a hybrid retrieval system using:
- BM25 keyword search
- Vector similarity search
- Reranking
- Code lineage expansion
- SQL lineage expansion
If the system finds a function call, it automatically retrieves the function definition. If it finds a dashboard query, it traces upstream tables and schemas. That extra context massively improved answer quality. Instead of returning shallow summaries, the system could explain:
- Where a metric comes from
- Which SQL transformations are involved
- Which upstream systems contribute to it
- Why two dashboards might disagree
That depth is what made the answers genuinely useful.
The Biggest Improvement: Human Feedback
The first version was only ~70% accurate.Good enough to feel useful. Dangerous enough to slowly lose trust.Prompt tuning helped a little. But the real improvement came from feedback loops.
Every response includes:
- 👍 Thumbs Up
- 👎 Thumbs Down
When users downvote an answer, the system logs:
- The prompt
- Retrieved context
- Routing decision
- Model output
A domain expert then reviews failures and creates verified corrections. Those corrections get stored as “Golden Conversations.” Later, when similar questions appear again, the system injects those verified examples directly into the prompt. So the system gradually learns from real production mistakes without needing fine-tuning. That feedback loop pushed the system from roughly 70% to around 80% reliable accuracy.
More importantly, users could actually feel the system improving over time.
Why This Matters As Companies Scale
The most valuable part of this system isn’t just better answers.It’s operational leverage. As organizations grow, teams spend huge amounts of time:
- Answering repetitive internal questions
- Debugging metric confusion
- Looking up historical decisions
- Handling simple operational requests
- Routing tickets manually
A system like this reduces that overhead significantly. Instead of scaling support linearly with company size, the AI layer absorbs a growing percentage of repetitive knowledge and operational work.
That saves:
- Engineering time
- Analytics bandwidth
- Support costs
- Operational delays
And because the system continuously learns through feedback loops, it becomes more valuable over time instead of degrading. The Executor Agent also creates an interesting middle ground between:
- Pure chatbots
- Full autonomous AI systems
The system can safely automate repetitive verified actions while still escalating risky or ambiguous requests to humans.That balance is probably where a lot of practical enterprise AI systems will evolve.
Final Thoughts
The biggest lesson from building this project was simple:
The model matters less than the system around the model.
Routing, retrieval quality, lineage expansion, safety layers, and feedback loops had a much bigger impact than swapping between foundation models. The most useful AI systems won’t just answer questions. They’ll understand organizational context, safely take action, continuously learn from failures, and reduce operational overhead as companies scale. That’s what ultimately transformed this project from:
“a cool AI demo”
into something teams could actually rely on.