From Pipeline Purgatory to Data Nirvana

The Ghost in the Machine: Remembering the Bad Old Days
Picture this: It's 2:47 AM on a Tuesday. My phone buzzes with that distinctive Slack notification sound that still triggers my fight-or-flight response. The nightly ETL job has failed. Again. Something about a malformed JSON response from an API that worked perfectly fine yesterday.
I drag myself to my laptop, squinting at terminal windows filled with stack traces that might as well be hieroglyphics. The culprit? Facebook changed a field from campaign_id to campaignId. One capital letter. Four hours of sleep, gone.
This was a day in my life circa 2018. Every pipeline was a house of cards built on quicksand during an earthquake. I had more monitoring dashboards than actual dashboards. My GitHub commits read like the diary of someone slowly losing their grip on reality: "Fixed the thing," "Really fixed the thing this time," "Why won't you work," "Please work," "IT WORKS DON'T TOUCH ANYTHING."
The worst part? I thought this was normal. We all did. It was our shared trauma, swapped like war stories at conferences over overpriced craft beer.
Then everything changed.
The Day I Stopped Writing ETL Scripts
Here's what happened: Our startup was growing faster than our infrastructure could handle. We had data scattered across seventeen different systems (yes, I counted), each with its own special snowflake API. Our analysts were begging for unified reporting. The CEO wanted real-time dashboards. And there I was, maintaining a Frankenstein's monster of Apache Airflow DAGs held together by environmental variables and prayer.
A colleague mentioned Fivetran casually, the way you'd recommend a good taco place. "It just works," he said. Those three words should have been a red flag. Nothing in data engineering "just works."
But desperation makes you try things.
I logged into Fivetran's interface expecting the usual: incomprehensible documentation, configuration files that require a PhD in YAML, and at least three authentication methods that would somehow still fail. Instead, I got something that looked suspiciously like it was designed by someone who actually had to use it.
The PostgreSQL connector asked for five things:
- Host
- Port
- Database name
- Username
- Password
That's it. No SSH tunnel configuration. No SSL certificate wrangling. No sacrificial offerings to the networking gods.
I clicked "Test Connection," fully prepared for the familiar red error message. Instead: a green checkmark. My production database was talking to Fivetran. Just like that.
The cynic in me was screaming. This had to be a trick.
The Moment Everything Clicked (Literally)
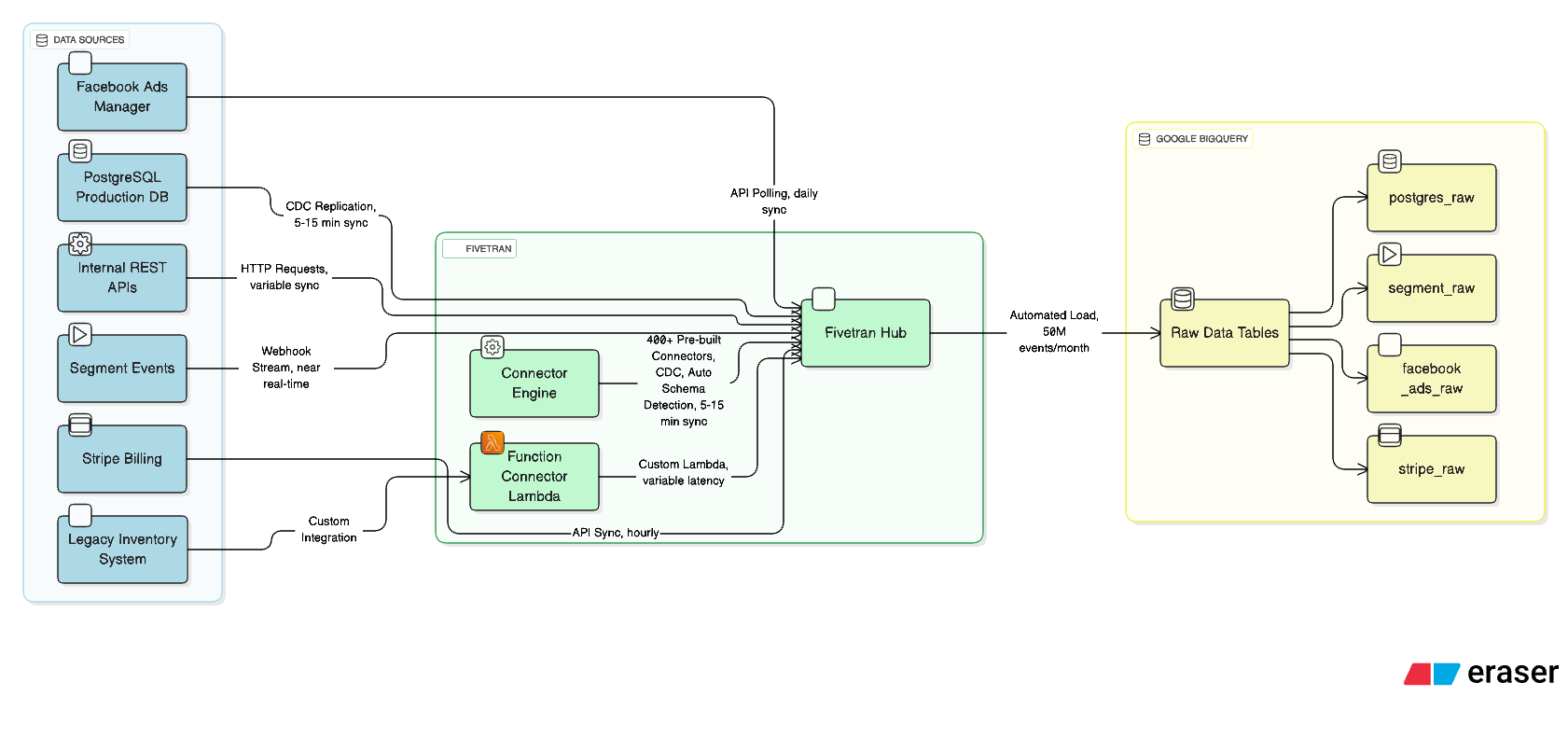
Within an hour—and I'm not exaggerating—I had connected:
- Our production PostgreSQL database (with CDC enabled for real-time replication)
- Segment's entire event stream (goodbye, manual webhook handlers)
- Facebook Ads Manager (no more rate limit nightmares)
- Stripe billing data (with automatic schema evolution)
- Even our quirky internal REST API (using Fivetran's Function connector)
Each connection followed the same pattern: authenticate, select tables, choose sync frequency, done. It was almost insulting how straightforward it was. Years of accumulated scar tissue from building these integrations by hand, and now they were just... checkboxes.
But here's where it got interesting: BigQuery.
Setting up BigQuery as the destination was equally anticlimactic. Fivetran asked for a service account key, I provided one, and suddenly data started flowing. Not trickling—flowing. Schemas materialized automatically in BigQuery, perfectly typed and organized. Tables appeared with names that actually made sense. Foreign keys were preserved. Data types were correctly mapped.
I watched the sync logs, waiting for the other shoe to drop. An out-of-memory error, maybe. A timeout. Something. Anything to justify my years of suffering.
Nothing happened. Well, that's not true—everything happened. The data moved. Reliably. Consistently. Boringly.
The Numbers That Made My CFO Smile
Let me paint you a picture with actual metrics:
Before Fivetran + BigQuery:
- Pipeline development time: 2-3 weeks per source
- Maintenance overhead: 40% of my time
- Data freshness: 1-24 hours (when things worked)
- Monthly infrastructure costs: ~$8,000 (servers, monitoring, alerting)
- Sleep quality: What sleep?
After Fivetran + BigQuery:
- Pipeline development time: 1-2 hours per source
- Maintenance overhead: Maybe 5% of my time
- Data freshness: 5-15 minutes for most sources
- Monthly costs: ~$3,000 for Fivetran, ~$1,500 for BigQuery
- Sleep quality: Like a baby (one that actually sleeps)
We were processing:
- 50 million Segment events monthly
- 200GB of PostgreSQL changes weekly
- 15 marketing platform integrations
- All updating every 15 minutes to 6 hours depending on the source
The kicker? We scaled from 10GB to 2TB of warehouse data without changing a single configuration. BigQuery just... handled it. No capacity planning meetings. No frantic vertical scaling at 11 PM on a Friday.
The Plot Twist: Learning to Let Go
Here's something nobody tells you about modern data infrastructure: the hardest part isn't technical—it's psychological.
I spent the first month after setting up Fivetran checking the logs obsessively. Surely something would break. I'd refresh the sync status page like it was my Twitter feed during an election. Every successful sync felt like I was getting away with something.
Then came the transformations. Fivetran deliberately doesn't handle the "T" in ELT, and initially, that bothered me. Where was my complete solution? But this constraint turned out to be liberating. We adopted dbt (data build tool) for transformations, and suddenly our analysts were writing their own SQL models. They weren't blocked on me anymore. They could iterate, experiment, fail fast—all the startup mantras we preached but rarely practiced.
Our dbt models looked something like this:
-- models/marts/marketing/campaign_performance.sql
WITH facebook_spend AS (
SELECT
date,
campaign_name,
SUM(spend) as daily_spend,
SUM(impressions) as impressions
FROM {{ ref('stg_facebook_ads__campaigns') }}
GROUP BY 1, 2
),
revenue_attribution AS (
SELECT
DATE(timestamp) as date,
utm_campaign as campaign_name,
SUM(revenue) as attributed_revenue
FROM {{ ref('fct_conversions') }}
WHERE utm_source = 'facebook'
GROUP BY 1, 2
)
SELECT
f.date,
f.campaign_name,
f.daily_spend,
f.impressions,
COALESCE(r.attributed_revenue, 0) as revenue,
SAFE_DIVIDE(COALESCE(r.attributed_revenue, 0), f.daily_spend) as roas
FROM facebook_spend f
LEFT JOIN revenue_attribution r USING(date, campaign_name)
Clean. Testable. Version controlled. The analysts owned it, understood it, and could modify it without fear of breaking production data flows.
The Uncomfortable Truths
Now, let's talk about the catches, because there are always catches.
The Price of Convenience:
Fivetran's MAR (Monthly Active Rows) pricing model is clever until you're syncing that chatty microservice that logs every mouse movement. We had one table that was 80% of our MAR but provided 2% of our value. The conversation went like this:
Me: "Do we really need to track every page scroll event?"
Product Manager: "Absolutely essential."
Me: "It's costing us $800/month just for scroll data."
Product Manager: "Oh. Maybe daily aggregates are fine."
The Connector Gap:
Fivetran has 400+ connectors, which sounds like a lot until you need number 401. We use this obscure inventory management system that was apparently coded in someone's garage in 2003. No connector. No API documentation. Just tears.
The solution? Fivetran's Function connector let me write a lightweight Lambda function to bridge the gap. It wasn't perfect, but it was manageable:
def handler(request, context):
# Fetch data from obscure system
weird_api_data = fetch_inventory_data()
# Transform to Fivetran format
return {
"state": {"last_updated": datetime.now().isoformat()},
"insert": {
"inventory_items": [
{"id": item["ID"], "quantity": item["QTY"],
"updated_at": item["LAST_MOD"]}
for item in weird_api_data
]
}
}
The Black Box Problem:
When something does go wrong (and it will, because computers), debugging can be frustrating. Fivetran's error messages sometimes read like fortune cookies: "Sync failed due to unexpected response." Thanks, very helpful.
The support team is responsive, but there's something unsettling about not being able to SSH into a server and fix things yourself. It's like being a mechanic who's only allowed to look at the dashboard lights.
The Philosophical Question Nobody Asks
Here's what keeps me up at night now (besides nothing, because my pipelines don't break): Have we traded too much control for convenience?
There's an entire generation of data engineers who will never know the joy of writing a custom PostgreSQL replication slot handler. They'll never experience the triumph of finally getting that SOAP API to work after three days of XML wrestling. Is something lost in this transaction?
Maybe. But you know what else is lost? Burnout. Frustration. The opportunity cost of building commodity infrastructure instead of solving actual business problems.
I used to pride myself on being able to build anything from scratch. Now I pride myself on knowing when not to. That's growth, I think.
The Verdict: A Love Letter to Boring Technology
Fivetran and BigQuery aren't sexy. They don't use the latest JavaScript framework (thank god). They won't impress anyone at a hackathon. They're boring in the best possible way—the way that electricity is boring, or indoor plumbing.
They work. Consistently. Reliably. Invisibly.
Our data team has tripled in size, but our data engineering team hasn't grown at all. We're handling 100x the data volume with the same headcount. Our analysts are self-sufficient. Our executives have real-time dashboards that actually show real-time data. Our customer success team can see user behavior patterns before users complain.
Most importantly, I get to focus on interesting problems now:
- Designing data models that will scale for the next five years
- Building predictive models instead of plumbing
- Actually talking to stakeholders about what insights they need
- Teaching analysts SQL optimization techniques
- Having lunch away from my desk
Is Fivetran + BigQuery the right choice for everyone? Probably not. If you're Netflix or Uber, you need custom everything. If you're a 5-person startup, you probably don't need it yet. But if you're in that sweet spot—growing fast, data becoming critical, engineering resources precious—this combination is magic.
The Final Plot Twist
Remember that obscure inventory system I mentioned? Last month, Fivetran released a connector for it. Turns out we weren't the only ones suffering.
I decommissioned my Lambda function with a single click. It felt like saying goodbye to an old friend—an annoying, high-maintenance friend who called at 3 AM, but still.
That's the thing about the modern data stack: it keeps getting better while you're sleeping. Literally sleeping. Eight hours a night. It's revolutionary.
So here's my advice to past me, and maybe to you: Stop building pipelines. Start building value. Let Fivetran and BigQuery handle the plumbing. Trust me, your future self will thank you.
And your phone? It can finally stay on silent.
P.S. - To the three people who will email me about how "real engineers build their own infrastructure": I built my own for seven years. I have the gray hairs and git history to prove it. Sometimes the most sophisticated engineering decision is choosing not to engineer something. Now if you'll excuse me, I have a 5 PM meeting to attend. At 5:01, I'll be logged off, because my pipelines don't need me anymore. And that's exactly how it should be.